
Data Ingestion with SQLAlchemy and Python
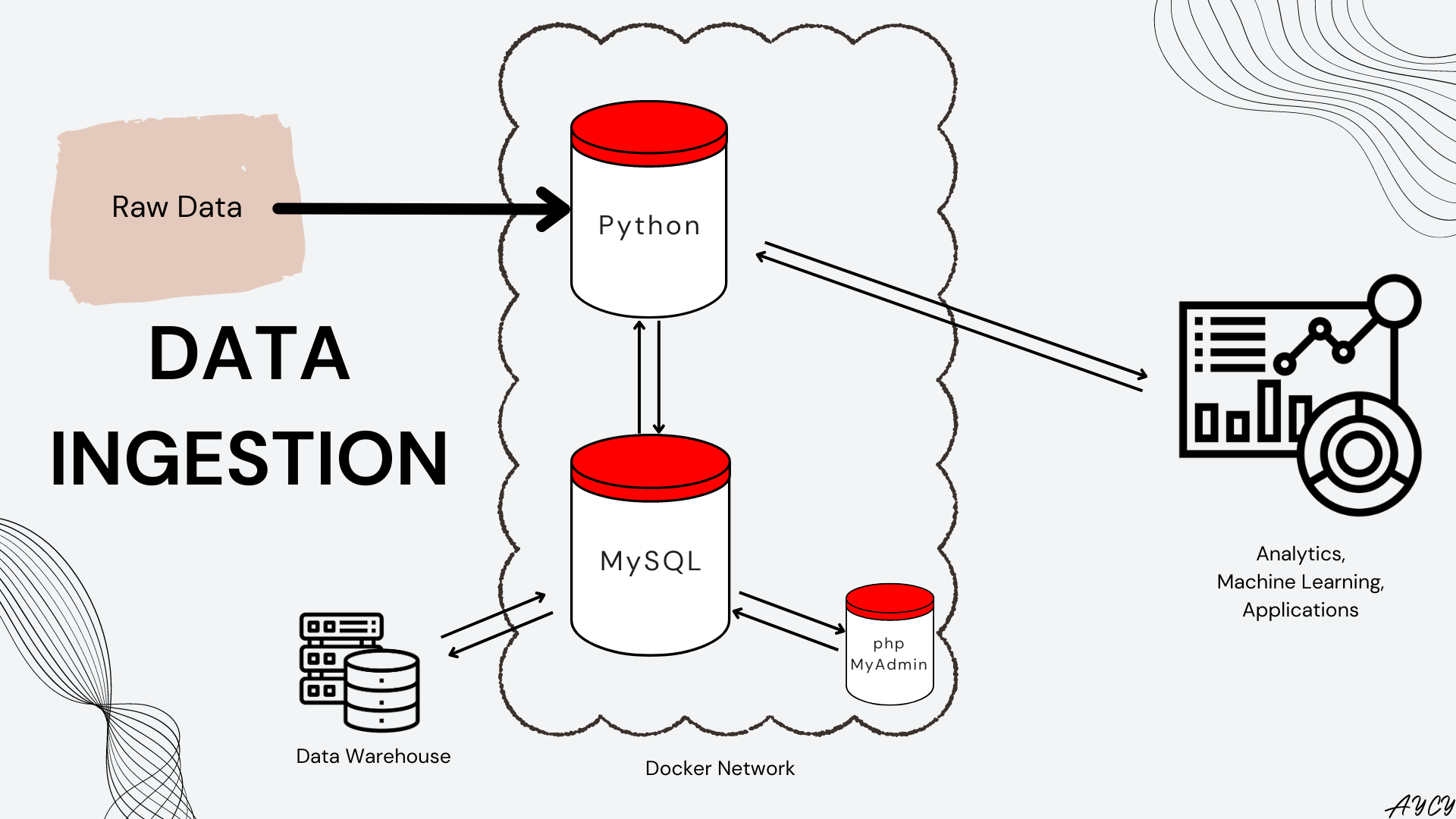 Figure 1. Overview of Data Ingestion Pipeline
Figure 1. Overview of Data Ingestion Pipeline
Previously, MySQL and phpMyAdmin were set up using Docker containers to store the bicycle rides data from Bixi. In this article, we explore how to Extract, Transform, and Load(ETL) the Bixi bicycle rides data into a MySQL database using SQLAlchemy in Python. A total 41 million rides between 2014 and 2022 had date columns converted to UTC timezone before being loaded into MySQL tables in chunks for better tracking and memory management. Finally, as a test, the ingested data were accessed using SQL statements within Python for analysis and visualization.
Motivation and Introduction
In the age of Big Data, it is unlikely that the required data is stored in a single MySQL database or even within a single DBMS. As such, rather than using a tool specific to MySQL, Python and the vast array of libraries available to it was chosen as a generic data processing tool for data ingestion into the MySQL database.
Aside from reducing dependence on specific tools, Python also acts as a consolidation point of data ingestion processes for easier maintenance, improvement and deployment of data pipelines.
Overview of Setup
Docker Enviroments
The environments needed can be easily replicated on any computer with Docker installed using this Docker compose file.
Place the Docker compose YAML file into your working directory, then run the below line in Terminal to setup the environment:
# Run below line in Terminal, with your current directory in Terminal same as your chosen working directory
docker-compose -f setup.yaml up
3 Docker containers and a Docker network connecting them all will be automatically setup:
- Container1: MySQL on port 3306
- Container2: phpMyAdmin on port 8080
- Container3:
jupyter/pyspark-notebookon port 10000, containing most Python data science pacakges and Apache Spark for dealing with big data later. details
Once the containers are up and running, access JupyterLab by going to localhost:10000 on a browser of your choice and inputting the access token, which can be found in the same terminal as shown below in blue.
 Figure 2. Access token for JupyterLab highlighted in blue
Figure 2. Access token for JupyterLab highlighted in blue
The contents of your working directory will be within the work folder shown below after accessing JupyterLab, and any changes made will be preserved.
 Figure 3. JupyterLab landing page
Figure 3. JupyterLab landing page
mysqlclient for SQLAlchemy
The docker image is missing the mysqlclient package required to create the SQLAlchemy engine that connects the Python container to the MySQL container.
To install the package, conda is accessed through the Python container’s terminal as shown below:
# 1. Opening a new terminal window, check the name of the Python container
docker ps
# 2. Activate an interactive terminal within the Python container
docker exec -it {name_of_python_container} /bin/bash
# 3. Use conda to install mysqlclient
conda install -c conda-forge mysqlclient
# 4. When done, exit the interactive terminal within the Docker container
exit
Import Packages and Define Functions
# For general data processing
import numpy as np
import pandas as pd
# For accessing and decompressing data files
import os
import zipfile
import shutil
# For measuring time and converting timezones
import pytz
import time
# For plotting
import matplotlib.pyplot as plt
import seaborn as sns
# For the engine that connects Python and MySQL
import sqlalchemy
def print_list(list):
'''
This functions takes a list and iterates over it to print out the contents of the list.
Inputs
---
list: a Python list
Outputs
---
printout of list content with index
'''
assert type(list) != "list", "Passed item is not a list"
assert len(list) != 0, "Passed list is empty."
for index, item in enumerate(list):
print(f"Item {index + 1} / {len(list)}: {item}")
def unzip_folder(zip_file_list):
'''
This function takes a list of ZIP files and iterates over each ZIP file to decompress the contents into a folder of the same name
The ZIP data must be placed within the 'data' folder of your working directory
Inputs
---
zip_file_list: a list of zip file names
Outputs
---
printout of current decompression progress
zip_df: a DataFrame containing the names of the ZIP file and its contents
'''
assert type(zip_file_list) != "list", "Passed item is not a list"
assert len(zip_file_list) != 0, "Passed list is empty."
# Initiate blank DataFrame to store log details about each unzipped file
zip_df = pd.DataFrame(
columns = ['zip_file', 'contents']
)
# Iterating over each zip file
for index, zip_file in enumerate(zip_file_list):
# Define path to each zip file
path_to_zip_file = 'data/' + zip_file
# Define directorty to dump all extracted zip files
directory_to_extract_to = 'data/' + zip_file[:-4]
# Create above directory
try:
os.mkdir(directory_to_extract_to)
except OSError as error:
print(error)
# With each zipfile opened as a zipfile object
with zipfile.ZipFile(path_to_zip_file,'r') as zip_ref:
# Create a temporary DataFrame to store log information about zipfiles
temp_df = pd.DataFrame(columns = ['zip_file','contents'])
# Gather the contents within each zipfile
temp_df['contents'] = zip_ref.namelist()
# Label from which zipfile were the contents extracted from
temp_df['zip_file'] = zip_file
# Concatenate the log for specific opened zipfile with rest of logs
zip_df = pd.concat([zip_df, temp_df]).reset_index(drop = True)
# Extract all contents out of zipfile into specified directory
zip_ref.extractall(directory_to_extract_to)
# Print status
print(f"Unzipped file {index + 1} of {len(zip_file_list)}.", end = '\r')
return zip_df
def flatten_subfolders(folder_list):
'''
This function takes a list of folders and iterates over each folder to flatten any subfolders within it, then removes the empty subfolders
The folders must be placed within the 'data' folder of your working directory
Inputs
---
folder_list: a list of folders containing subfolders
Outputs
---
printout of current flattening progress
'''
assert type(folder_list) != "list", "Passed item is not a list"
assert len(folder_list) != 0, "Passed list is empty."
# Iterating through each folder
for index, folder in enumerate(folder_list):
# Define main folder
main_folder = 'data/' + folder
# Identify all subfolders within the main folder
subfolders = [folder.path for folder in os.scandir(main_folder) if folder.is_dir()]
# Iterating through each subfolder
for subfolder in subfolders:
# Iterating through each file within each subfolder
for file in os.listdir(subfolder):
# Define origin filepath, i.e. the file within the subfolder to be moved
origin = os.path.join(subfolder, file)
# Define destination filepath, i.e. the main folder with all the other data
destination = os.path.join(main_folder, file)
# Move file from origin within subfolder out to main folder
shutil.move(origin,destination)
# Remove subfolder after all files have been moved
shutil.rmtree(subfolder)
# Print status
print(f"Flattened subfolder {index + 1} of {len(folder_list)}.", end = '\r')
Decompress the ZIP Data
Before making any decisions in database architecture and design, it is imperative to understand what the data will be used for. For this case, the Bixi bicycle ride data will be:
- combined with rides data from other companies to generate an analytics dashboard to monitor operations and membership programs.
- used for perform time series analysis and machine learning to possibly predict bicycle needs across stations and times of day for better bicyle distribution
Previously, the rides data were web-scraped off from the Bixi website and stored as unpacked ZIP files in a single folder.
A problem was that the granularity of data across years for station data was not consistent, causing difficulty in assigning stations data to rides data. Thus, to remedy this, we will be starting from the ZIP files, where it is known for certain which ride files correspond to which station files.
# Use web-scrape log files to identify the zip files previously web-scrapped
log_df = pd.read_csv('logs/log_df.csv')
# Visually examine the zip folders
zip_file_list = log_df.loc[:,'file_name'].to_list()
print_list(zip_file_list)
Item 1 / 16: biximontrealrentals2014-f040e0.zip
Item 2 / 16: biximontrealrentals2015-69fdf0.zip
Item 3 / 16: biximontrealrentals2016-912f00.zip
Item 4 / 16: biximontrealrentals2017-d4d086.zip
Item 5 / 16: biximontrealrentals2018-96034e.zip
Item 6 / 16: biximontrealrentals2019-33ea73.zip
Item 7 / 16: biximontrealrentals2020-8e67d9.zip
Item 8 / 16: 2021-donnees-ouvertes-464ae6.zip
Item 9 / 16: 20220104-stations-f82036.zip
Item 10 / 16: 20220105-donnees-ouvertes-0d544b.zip
Item 11 / 16: 20220106-donnees-ouvertes-f45195.zip
Item 12 / 16: 20220107-donnees-ouvertes-8aa623.zip
Item 13 / 16: 20220108-donnees-ouvertes-816bd4.zip
Item 14 / 16: 20220109-donnees-ouvertes-519d43.zip
Item 15 / 16: 20220110-donnees-ouvertes-5079e8.zip
Item 16 / 16: 20220111-donnees-ouvertes-e1c737.zip
The bicycle rides data were contained in 16 ZIP files, with one file for each year except 2022. The contents within each ZIP file were decompressed and unpacked into folders of the same name.
# Unzip all 16 folders
zip_df = unzip_folder(zip_file_list)
# Store the ZIP file logs
zip_df.to_csv('logs/unzip_data.csv', index = False)
Unzipped file 16 of 16.
Then all subfolders within each unzipped rides data folder were flattened to access the files easily.
# Define list of folders to perform flattening for: exclude ZIP files and hidden files
folder_list = [folder for folder in os.listdir('data/') if folder[-4:] != '.zip' and folder[0:1] != '.']
# Flatten all subfolders within the 16 unzipped folders
flatten_subfolders(folder_list)
Flattened subfolder 16 of 16.
# Visually examine flattened folders
print_list(folder_list)
Item 1 / 16: 2021-donnees-ouvertes-464ae6
Item 2 / 16: 20220104-stations-f82036
Item 3 / 16: 20220105-donnees-ouvertes-0d544b
Item 4 / 16: 20220106-donnees-ouvertes-f45195
Item 5 / 16: 20220107-donnees-ouvertes-8aa623
Item 6 / 16: 20220108-donnees-ouvertes-816bd4
Item 7 / 16: 20220109-donnees-ouvertes-519d43
Item 8 / 16: 20220110-donnees-ouvertes-5079e8
Item 9 / 16: 20220111-donnees-ouvertes-e1c737
Item 10 / 16: biximontrealrentals2014-f040e0
Item 11 / 16: biximontrealrentals2015-69fdf0
Item 12 / 16: biximontrealrentals2016-912f00
Item 13 / 16: biximontrealrentals2017-d4d086
Item 14 / 16: biximontrealrentals2018-96034e
Item 15 / 16: biximontrealrentals2019-33ea73
Item 16 / 16: biximontrealrentals2020-8e67d9
Sample the Raw Data
As pandas attempts to automatically recognized data types upon import, bash on terminal was chosen to examine the raw data.
Bash with its simplicity is much faster than Pandas in counting rows and displays the data as plain text without any consideration of data types, making it an excellent tool for quickly examining large data.
# Peform row count for the files in the 2014 folder using terminal
# Run this for loop line by line in terminal
for file in *.csv
do
wc -l $file
done
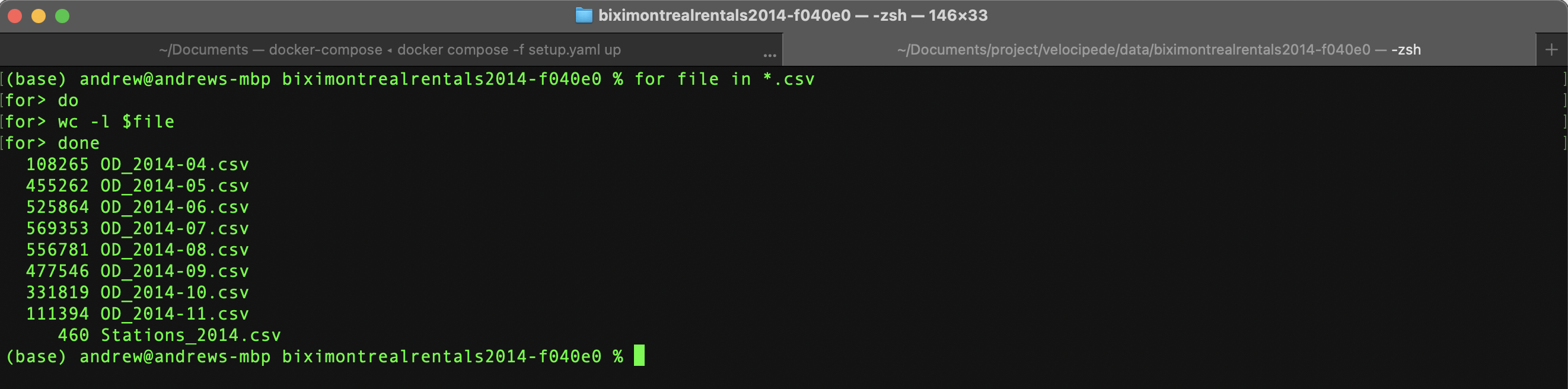 Figure 4. Row count for each file using bash
Figure 4. Row count for each file using bash
Taking the sum of all the rows above, there are roughly 3 million rides in the year 2014 alone. This means that the whole dataset is estimated to be at least 27 million rows of data detailing the Bixi bicycle rides in Montreal over 9 years.
The sheer number of rows justifies the use of Python and MySQL over traditional spreadsheets like Excel as the latter are unable to handle such large data.
# Visually examine first 10 rows of rides data in the file OD_2014-10.csv within the year 2014
less -NS OD_2014-10.csv | head
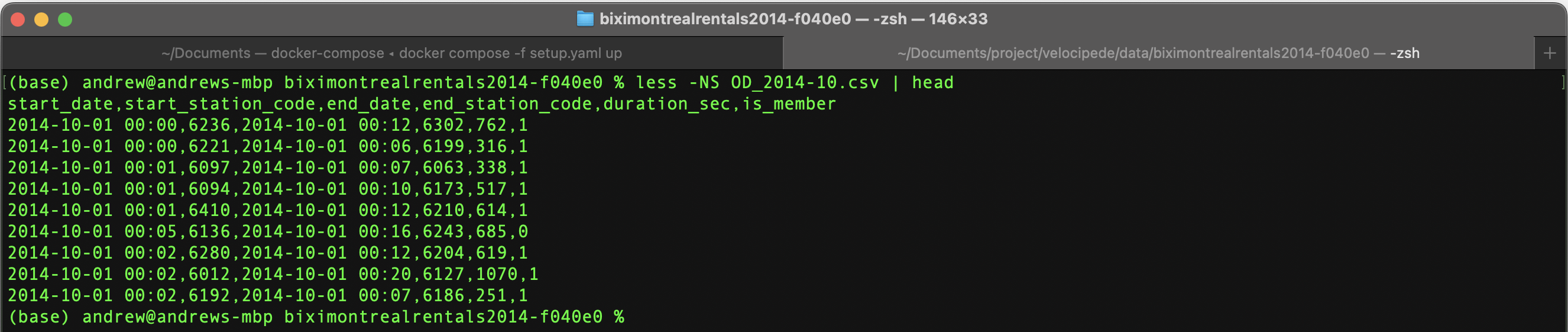 Figure 5. First 10 rows for rides data
Figure 5. First 10 rows for rides data
From above, the rides data were observed to contain 6 columns:
start_date: the datetime when a Bixi bicycle is checked out from a dockstart_station_code: the docking station where the Bixi bicycles was checked out fromend_date: the datetime when a Bixi bicycle is returned to a dockend_station_code: the docking station where the checked out bicycle was returned toduration_sec: the total time of the rideis_member: the membership status of the customer who used the Bixi bicycle
Repeating the procedure for bicycle docking stations data:
code: the code of the station, used to map station info to rides tablename: the human readable name of the stationlatitude: the latitude of the stationlongitude: the longitude of the station
Designing Tables and Relationships
Now that we have a better understanding of the data, it is clear that at least two tables need to be created in the database: rides and stations.
The rides table will contain the data about each ride, and, is connected to the stations table using the code column. But, depending on time, the exact longitude and latitude of each docking station may change due to circumstances such as road repairs. This implies that the stations data for 2014 may not be applicable to 2015 and other years. In terms of impact, distance per ride calculations will change depending on latitude and longitude, and should be considered when deciding station locations.
Furthermore, as mentioned above, unlike all other years which had 1 stations table per year, the year 2022 had 1 stations table per month, complicating the granularity and thus the method of connecting the rides and stations tables consistently throughout the years.
To solve this issue of granularity, a third table is created, containing the details on how to join the rides and stations table for each year. This table is called a join table and can be generated by examining the contents of each folder. Each folder contains a file with the word station in the file name for the station data while the other files are ride data. Using this pattern the Entity Relationship Diagram below can be drawn:
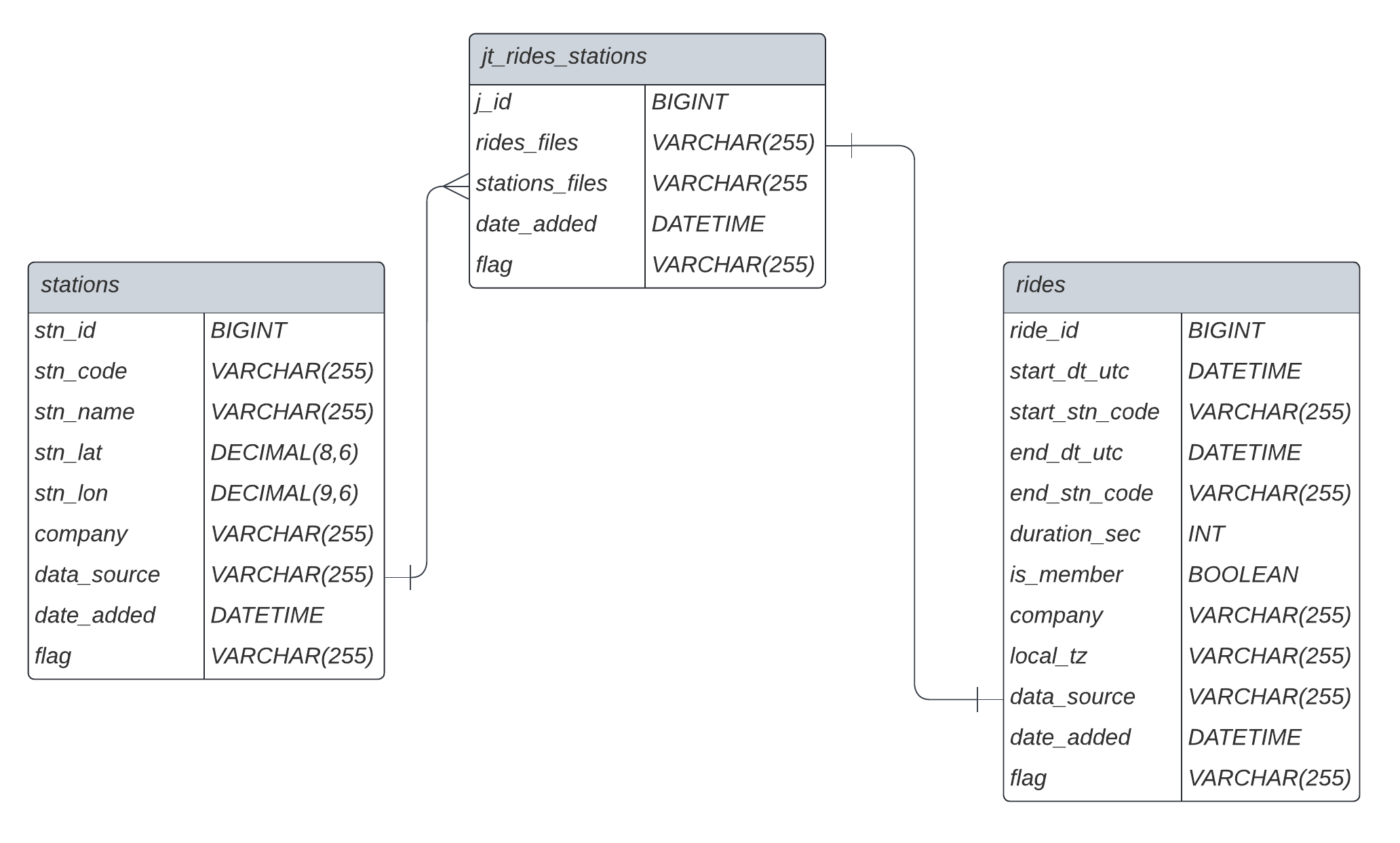 Figure 6. Entity Relationship Diagram (ERD) between
Figure 6. Entity Relationship Diagram (ERD) between rides and stations table
Design Considerations:
idcolumns all have data type of BIGINT, which allows for unsigned numbers up to 2^64-1.idcolumns were created instead of using natural primary keys to:- better identify specific rows
- avoid dependence of primary keys on business model, i.e. a natural key combination today may be irrelevant in future years.
companyhas been added to bothridesandstationsin anticipation of rides data coming from outside Bixidata_source,date_added, andflagare for book-keeping purposes, withflagused as a flag for deletion. This avoids the need to actually delete any rows.stn_latandstn_lonhave 9 significant digits and 6 decimal places. Latitude and longitude will always be below 4 digits before the decimal point, and, 6 decimal places after the decimal point provides accuracy of 0.111m at the equator, which is sufficient in identifying the exact location of a bicycle station.
Executing Database Design
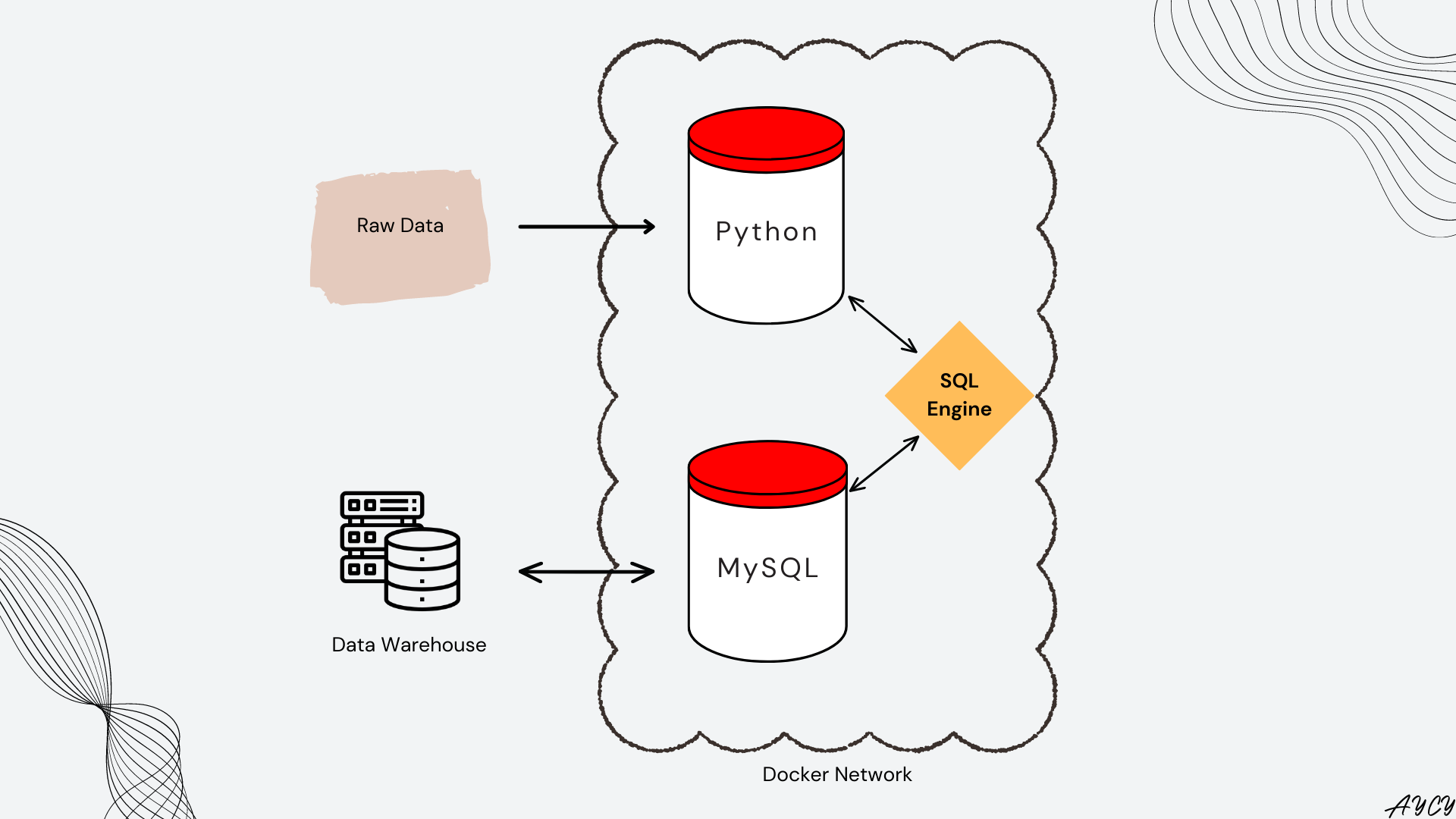 Figure 7. System Architecture for Data Ingestion
Figure 7. System Architecture for Data Ingestion
Figure 7 shows only the processes involved in data ingestion with the addition of a SQL Engine represented by the orange diamond. The SQL Engine allows for Python to send and receive SQL query statements from MySQL, and is built using the SQLAlchemy package. Specific documentation for MySQL here.
Create SQL Engine
To create the engine, the create_engine method from SQLAlchemy was used:
# Create the connection engine
engine = sqlalchemy.create_engine(
"mysql+mysqldb://root:rootroot@mysql:3306"
)
mysql+mysqldbare the drivers frommysqlclientroot:rootrootstands for the username:password@mysql:3306refers to port 3306 in themysqlDocker container
NOTE: the with statement was used when establishing connections using the engine to MySQL as it ensures that the connection is automatically closed once the SQL query is executed.
Examine Existing Databases
The databases in MySQL can be directly inspected from Python using the inspect method on the SQL Engine object created. The result is an inspector object, which can then be accessed to get available databases. This inspection method can be applied to the engine to gather databases (schema), tables, and even columns as shown later.
# Create an inspection object
inspector = sqlalchemy.inspect(engine)
print(type(inspector))
<class 'sqlalchemy.engine.reflection.Inspector'>
# Store the database names in a list
databases = inspector.get_schema_names()
# Print out list for inspection
print_list(databases)
Item 1 / 5: information_schema
Item 2 / 5: mysql
Item 3 / 5: performance_schema
Item 4 / 5: sys
Item 5 / 5: test_db
By default, a fresh installation of MySQL should show the above 4 databases. Next we need to create a new database to store the Bixi rides data.
Create a Database
SQLAlchemy allows the use of conventional SQL statements in Python using the text method as shown below:
# Establish a connection to MySQL using the engine
with engine.connect() as conn:
# Creates a SQL statement, in this case to create a database called velocipede
sql_stmt = sqlalchemy.text("""CREATE DATABASE IF NOT EXISTS velocipede""")
# Send the SQL statement to MySQL
conn.execute(sql_stmt)
To verify the success of above SQL statement, the inspect method may be repeated.
# Update inspector object
inspector = sqlalchemy.inspect(engine)
databases = inspector.get_schema_names()
print_list(databases)
Item 1 / 6: information_schema
Item 2 / 6: mysql
Item 3 / 6: performance_schema
Item 4 / 6: sys
Item 5 / 6: test_db
Item 6 / 6: velocipede
Create Tables within a Database
Now that the database velocipede has been created, the next step is to create the 3 tables defined in the ERD. But first, the engine can be updated with another parameter to point specifically to the velocipede database, avoiding the need to specify a database when writing SQL statements.
# Redefine new engine to point to newly created database by adding it after port 3306
engine = sqlalchemy.create_engine(
"mysql+mysqldb://root:rootroot@mysql:3306/velocipede"
)
Then, the inspect method was used again but this time to gather table instead of schema(database) names. Since this is a new database, no tables were expected.
# Create inspector object for tables within velocipede
inspector = sqlalchemy.inspect(engine)
tables = inspector.get_table_names()
tables
[]
rides Table
A benefit of using SQLAlchemy is that users can use SQL statements within Python. Although not covered in this notebook, SQLAlchemy does offer a comprehensive standardized Pythonic syntax for accessing various DBMS in their documentation.
# Create a new table for rides
with engine.connect() as conn:
# Generate SQL statement using text
sql_stmt = sqlalchemy.text(
"""
CREATE TABLE IF NOT EXISTS rides (
# columns regarding rides, assume each ride unique given no ride_id provided
ride_id BIGINT NOT NULL AUTO_INCREMENT,
start_dt_utc DATETIME NOT NULL,
start_stn_code VARCHAR(255) NOT NULL,
end_dt_utc DATETIME NOT NULL,
end_stn_code VARCHAR(255) NOT NULL,
duration_sec INT NOT NULL,
is_member BOOLEAN,
company VARCHAR(255) NOT NULL,
local_tz VARCHAR(255) NOT NULL,
# columns for data maintenance
data_source VARCHAR(255) NOT NULL,
date_added DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
flag VARCHAR(255),
# Each ride is unique
CONSTRAINT ride_uid UNIQUE (ride_id)
)
"""
)
# Execute the SQL statement
conn.execute(sql_stmt)
Again the inspect method can be applied to check if both the table and the columns within it have been created accordingly.
# Create inspector object for tables and columns
inspector = sqlalchemy.inspect(engine)
# Use inspector to get table names
tables = inspector.get_table_names()
print_list(tables)
Item 1 / 1: rides
# Use the same inspector to get column names, specifiying table name as an argument
columns = inspector.get_columns('rides')
print_list(columns)
Item 1 / 12: {'name': 'ride_id', 'type': BIGINT(), 'default': None, 'comment': None, 'nullable': False, 'autoincrement': True}
Item 2 / 12: {'name': 'start_dt_utc', 'type': DATETIME(), 'default': None, 'comment': None, 'nullable': False}
Item 3 / 12: {'name': 'start_stn_code', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 4 / 12: {'name': 'end_dt_utc', 'type': DATETIME(), 'default': None, 'comment': None, 'nullable': False}
Item 5 / 12: {'name': 'end_stn_code', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 6 / 12: {'name': 'duration_sec', 'type': INTEGER(), 'default': None, 'comment': None, 'nullable': False, 'autoincrement': False}
Item 7 / 12: {'name': 'is_member', 'type': TINYINT(display_width=1), 'default': None, 'comment': None, 'nullable': True, 'autoincrement': False}
Item 8 / 12: {'name': 'company', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 9 / 12: {'name': 'local_tz', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 10 / 12: {'name': 'data_source', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 11 / 12: {'name': 'date_added', 'type': DATETIME(), 'default': 'CURRENT_TIMESTAMP', 'comment': None, 'nullable': False}
Item 12 / 12: {'name': 'flag', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': True}
As seen above, the rides table and its 12 columns have been created as specified.
stations Table
The same procedure is repeated to create the stations and jt_rides_stations tables.
# Create `stations` table
with engine.connect() as conn:
sql_stmt = sqlalchemy.text(
"""
CREATE TABLE IF NOT EXISTS stations (
# columns regarding rides, assume each ride unique given no ride_id provided
stn_id BIGINT NOT NULL AUTO_INCREMENT,
stn_code VARCHAR(255) NOT NULL,
stn_name VARCHAR(255) NOT NULL,
stn_lat DECIMAL(9,6) NOT NULL,
stn_lon DECIMAL(9,6) NOT NULL,
company VARCHAR(255) NOT NULL,
# columns for data maintenance
data_source VARCHAR(255) NOT NULL,
date_added DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
flag VARCHAR(255),
# Each ride is unique
CONSTRAINT stn_uid UNIQUE (stn_id)
)
"""
)
conn.execute(sql_stmt)
The inspect method was used to verify the creation of the table stations.
# Check if table was created
inspector = sqlalchemy.inspect(engine)
tables = inspector.get_table_names()
print_list(tables)
Item 1 / 2: rides
Item 2 / 2: stations
# Check if columns were created
columns = inspector.get_columns('stations')
print_list(columns)
Item 1 / 9: {'name': 'stn_id', 'type': BIGINT(), 'default': None, 'comment': None, 'nullable': False, 'autoincrement': True}
Item 2 / 9: {'name': 'stn_code', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 3 / 9: {'name': 'stn_name', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 4 / 9: {'name': 'stn_lat', 'type': DECIMAL(precision=9, scale=6), 'default': None, 'comment': None, 'nullable': False}
Item 5 / 9: {'name': 'stn_lon', 'type': DECIMAL(precision=9, scale=6), 'default': None, 'comment': None, 'nullable': False}
Item 6 / 9: {'name': 'company', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 7 / 9: {'name': 'data_source', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 8 / 9: {'name': 'date_added', 'type': DATETIME(), 'default': 'CURRENT_TIMESTAMP', 'comment': None, 'nullable': False}
Item 9 / 9: {'name': 'flag', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': True}
jt_rides_stations Table
Finally, the join table between stations and rides was created.
# Create `jt_rides_stations` table
with engine.connect() as conn:
sql_stmt = sqlalchemy.text(
"""
CREATE TABLE IF NOT EXISTS jt_rides_stations (
# columns regarding which station file matches which ride file
j_id BIGINT NOT NULL AUTO_INCREMENT,
ride_files VARCHAR(255) NOT NULL,
station_files VARCHAR(255) NOT NULL,
# columns for data maintenance
date_added DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
flag VARCHAR(255),
# Each ride is unique
CONSTRAINT j_id UNIQUE (j_id),
CONSTRAINT join_check UNIQUE(ride_files, station_files)
)
"""
)
conn.execute(sql_stmt)
# Check if table was created
inspector = sqlalchemy.inspect(engine)
tables = inspector.get_table_names()
print_list(tables)
Item 1 / 3: jt_rides_stations
Item 2 / 3: rides
Item 3 / 3: stations
# Check if columns were created
columns = inspector.get_columns('jt_rides_stations')
print_list(columns)
Item 1 / 5: {'name': 'j_id', 'type': BIGINT(), 'default': None, 'comment': None, 'nullable': False, 'autoincrement': True}
Item 2 / 5: {'name': 'ride_files', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 3 / 5: {'name': 'station_files', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': False}
Item 4 / 5: {'name': 'date_added', 'type': DATETIME(), 'default': 'CURRENT_TIMESTAMP', 'comment': None, 'nullable': False}
Item 5 / 5: {'name': 'flag', 'type': VARCHAR(length=255), 'default': None, 'comment': None, 'nullable': True}
Populate the Tables (ETL)
Next, the data was extracted from each file with date columns transformed from Montreal time to Coordinated Universal Time (UTC) before being finally loaded into the MySQL database.
This transformation is necessary to standardize all time stored within the MySQL database as UTC, especially when rides data from cities with different timezones will be stored in the future.
If needed, local time can be generated by converting back to Montreal time using the local_tz column. The timezone conversion is performed using pandas tz methods and requires the pytz library, which contains world timezone definition for Python.
Define Constants for Data Ingestion
# Define timezone objects
montreal_tz_name = 'Canada/Eastern'
montreal_tz = pytz.timezone(montreal_tz_name)
utc_tz = pytz.timezone('UTC')
company = 'Bixi'
# Define list of columns to be read from rides CSVs
rides_columns = [
'start_date',
'start_station_code',
'end_date',
'end_station_code',
'duration_sec',
'is_member'
]
# Define data types for above columns
# Note date columns were loaded as string here for more specific dt conversion later
rides_dtypes = {
'start_date' : 'string',
'start_station_code' : 'string',
'end_date' : 'string',
'end_station_code' : 'string',
'duration_sec' : 'int',
'is_member' : 'boolean'
}
# Define list of columns to be read from stations CSVs
stations_columns = [
'code',
'name',
'latitude',
'longitude'
]
# Define data types for above columns
stations_dtypes = {
'code':'string',
'name':'string',
'latitude': float,
'longitude':float
}
# Define list of columns to be read from join table
jt_columns = [
'ride_files',
'station_files'
]
# Define data type for each column
jt_dtypes = {
'ride_files':'string',
'station_files':'string'
}
# Some files were found to have inconsistent columns
# These files were excluded for now and have to be examined later
folders_to_exclude = [
'20220111-donnees-ouvertes-e1c737',
'20220110-donnees-ouvertes-5079e8',
'20220109-donnees-ouvertes-519d43'
]
# Update folder_list with folders to exclude
folder_list = [folder for folder in folder_list if folder not in folders_to_exclude]
Rides and Stations Data
The code block iterates over each folder and file, identifies the file as either a rides or stations file, then performs the appropriate ETL before data ingestion into the MySQL database.
Specifically:
ridesdata: convert datetime columns to UTC timezone, then ingest into MySQL databasestationsdata: no ETL, straight to MySQL database
Note, as the data files are quite large (over a million rows), chunking was used to break down the data into smaller parts. This prevents memory from being entirely used up and makes it easier to identify problem chunks.
# Initiate counter for total run-time
total_time = 0
# Iterate over each unzipped folder, with 2022 Sep, Oct, Nov excluded
for index, folder in enumerate(folder_list):
# Get the files within each unzipped folder
folder_contents = os.listdir('data/' + folder)
# Identify file as stations or rides
stations_files = [file for file in folder_contents if 'station' in file.lower()]
rides_files = [file for file in folder_contents if file not in stations_files]
# Iterate over each file to load into mySQL
for file_index, file in enumerate(folder_contents):
# For ride files
if file in rides_files:
# Break each CSV file up into chunks and iterate over each chunk
for chunk_index, chunk in enumerate(
pd.read_csv(
'data/' + folder + '/' + file,
header = 0, # Ignore header column
names = rides_columns, # Use these as column names instead
usecols = rides_columns, # Only extract specified columns
dtype = rides_dtypes, # Apply these data types
chunksize = 500_000
)
):
# Initiate timer
start_time = time.perf_counter()
# Array to deal with ambiguous timezone due to Daylight Saving Time
infer_dst = np.array([False] * chunk.shape[0])
# Convert timezone from local time to UTC for date columns
for col in ['start_date', 'end_date']:
# Convert date column from string to datetime index (dti) based on ISO format
dti = pd.to_datetime(chunk[col], format = "ISO8601")
# Add timezone detail to the datetime index
dti = dti.dt.tz_localize(tz = montreal_tz, ambiguous = infer_dst)
# Convert datetime to UTC timezone
dti = dti.dt.tz_convert(tz = utc_tz)
# Convert dti with tz back to dti for storage into DB
chunk.loc[:,col] = dti.dt.tz_convert(tz = None)
# Define fixed columns specific to data
chunk['company'] = company
chunk['data_source'] = file
chunk['local_tz'] = montreal_tz_name
# Rename columns within each chunk to match mySQL column names
chunk.rename(
{
'start_station_code' : 'start_stn_code',
'end_station_code' : 'end_stn_code',
'start_date' : 'start_dt_utc',
'end_date' : 'end_dt_utc'
},
axis = 'columns',
inplace = True
)
# Send processed chunk to SQL
with engine.connect() as conn:
chunk.to_sql(
'rides',
con = conn,
schema = 'velocipede',
if_exists = 'append',
index = False
)
# Rest for 0.1 seconds to avoid flooding MySQL server
time.sleep(0.1)
# Initiate end timer
end_time = time.perf_counter()
# Count time taken, update and display total time and progress
time_taken = np.round(end_time - start_time,3)
total_time += time_taken
print(f"Processed folder {index + 1}: {folder}; file {file_index+1}:{file}; chunk {chunk_index+1}; time taken {time_taken}s; running time {np.round(total_time,3)}s", end = "\r")
# Case for station files
else:
# Initiate start timer
start_time = time.perf_counter()
# Break each CSV file up into chunks and iterate over each chunk
for chunk_index, chunk in enumerate(
pd.read_csv(
'data/' + folder + '/' + file,
header = 0,
names = stations_columns,
usecols = stations_columns,
dtype = stations_dtypes,
chunksize = 500_000
)
):
# Add fixed columns
chunk['company'] = company
chunk['data_source'] = file
# Rename columns to match database
chunk.rename(
{
'code' : 'stn_code',
'name' : 'stn_name',
'latitude' : 'stn_lat',
'longitude' : 'stn_lon'
},
axis = 'columns',
inplace = True
)
# Send processed chunk to SQL
with engine.connect() as conn:
chunk.to_sql(
'stations',
con = conn,
schema = 'velocipede',
if_exists = 'append',
index = False
)
# Rest for 0.1 seconds to avoid flooding MySQL server
time.sleep(0.1)
# Initiate end timer
end_time = time.perf_counter()
# Count time taken, update and display total time and progress
time_taken = np.round(end_time - start_time,3)
total_time += time_taken
print(f"Processed folder {index + 1}: {folder}; file {file_index+1}:{file}; chunk {chunk_index+1}; time taken {time_taken}s; running time {np.round(total_time,3)}s", end = "\r")
# Once loop ends, print done message.
print(f"All data loaded into mySQL.")
All data loaded into mySQL.ntrealrentals2020-8e67d9; file 2:stations.csv; chunk 1; time taken 0.149s; running time 1959.548s.776s11se 547.041s
Join Table
The join table between stations and rides was created by matching the station file name to the ride files within each unzipped folder.
# Initiate an empty DataFrame to store data
join_table = pd.DataFrame()
# Iterate over each unzipped folder
for index, folder in enumerate(folder_list):
# Get the files within each unzipped folder
folder_contents = os.listdir('data/'+ folder)
# Identify file as stations or rides
station_files = [file for file in folder_contents if 'station' in file.lower()]
ride_files = [file for file in folder_contents if file not in station_files]
# Create a temporary DataFrame where names of ride_files are stored
temp_df = pd.DataFrame({'ride_files':ride_files})
# The number of station files per unzipped folder should be 1
if len(station_files) == 1:
# Store the station_file name, pandas automatically repeats it for each ride file
temp_df['station_files'] = station_files[0]
else:
print("Check station file in folder {index + 1} : {folder}.")
# Combine temporary DataFrame with join_table
join_table = pd.concat(
[join_table,temp_df],
axis = 0,
).reset_index(drop = True)
# Print progress
print(f'Processing folder {index+1} of {len(folder_list)}, folder: {folder}', end = '\r')
Processing folder 13 of 13, folder: biximontrealrentals2020-8e67d94
As observed below, the join table captures the unstandardized granularity of the stations data for each rides file.
# Visually examine the join_table
join_table.head(15)
| ride_files | station_files | |
|---|---|---|
| 0 | 2021_donnees_ouvertes.csv | 2021_stations.csv |
| 1 | 20220104_donnees_ouvertes.csv | 20220104_stations.csv |
| 2 | 20220105_donnees_ouvertes.csv | 20220105_stations.csv |
| 3 | 20220106_donnees_ouvertes.csv | 20220106_stations.csv |
| 4 | 20220107_donnees_ouvertes.csv | 20220107_stations.csv |
| 5 | 20220108_donnees_ouvertes.csv | 20220108_stations.csv |
| 6 | OD_2014-04.csv | Stations_2014.csv |
| 7 | OD_2014-05.csv | Stations_2014.csv |
| 8 | OD_2014-06.csv | Stations_2014.csv |
| 9 | OD_2014-07.csv | Stations_2014.csv |
| 10 | OD_2014-08.csv | Stations_2014.csv |
| 11 | OD_2014-09.csv | Stations_2014.csv |
| 12 | OD_2014-10.csv | Stations_2014.csv |
| 13 | OD_2014-11.csv | Stations_2014.csv |
| 14 | OD_2015-04.csv | Stations_2015.csv |
Finally, the join table was loaded onto MySQL.
with engine.connect() as conn:
join_table.to_sql(
'jt_rides_stations',
con = conn,
schema = 'velocipede',
if_exists = 'append',
index = False
)
Testing Database with SQL Statements
After loading the data into MySQL, SQL statements can now be executed using the same SQL Engine to cross-check and explore the data. Below are two samples.
Sum of Rides by Year
A SQL statement was used as an argument in pandas’s read_sql method to send and receive queries from MySQL.
# Establish a connection to MySQL using the engine
with engine.connect() as conn:
# A SQL query that counts the number of rides by year
sql_stmt = sqlalchemy.text(
"""
SELECT
YEAR(start_dt_utc) AS year,
COUNT(*) AS rides
FROM
rides
GROUP BY
year
ORDER BY
year ASC
"""
)
# start_timer
start_time = time.perf_counter()
# Use above SQL statement as argument, specifying index_col as year
result_df = pd.read_sql(
sql_stmt,
con = conn,
index_col = 'year'
)
# end_timer
end_time = time.perf_counter()
time_taken = np.round(end_time - start_time,3)
print(f"Time taken to run SQL query: {time_taken} seconds.")
Time taken to run SQL query: 35.115 seconds.
The results from the SQL query are automatically stored inside a pandas DataFrame as shown below. The time taken was 29 seconds, much longer than regular SQL queries. This was expected as the dataset is 40.94 million rows large.
print(f"Total number of Bixi rides between 2014 and 2022 Aug: {np.round(result_df['rides'].sum()/1_000_000,2)} million.")
Total number of Bixi rides between 2014 and 2022 Aug: 40.94 million.
# Examine results from SQL query
display(result_df)
| rides | |
|---|---|
| year | |
| 2014 | 3136276 |
| 2015 | 3443883 |
| 2016 | 4000080 |
| 2017 | 4740357 |
| 2018 | 5277541 |
| 2019 | 5597845 |
| 2020 | 3264741 |
| 2021 | 5566351 |
| 2022 | 5913225 |
Finally, the grouped data from the SQL query can be used to plot the number of rides by year as shown below:
# Initiate figure object
plt.figure()
# Using pandas built-in integration with matplotlib.pyplot
result_df.plot(
y = 'rides',
linestyle = '--',
marker = 'x',
legend = None,
ax = plt.gca()
)
# Add y-label and figure title
plt.ylabel('Number of Bixi rides (millions)')
plt.title('Figure 8. Number of Bixi Rides vs Year', y = -0.2)
# Annotate for Covid-19
plt.annotate(
text = 'covid-19',
xy = (2020,3_264_741),
xytext = (2018,3_500_000),
arrowprops = dict(facecolor='black', shrink=0.05)
)
# Annotate for 2022 excluding data for Sep, Oct, and Nov
plt.annotate(
text = '2022 excl. \nSep, Oct, Nov',
xy = (2022,5_913_225),
xytext = (2021.5,5_000_000),
arrowprops = dict(facecolor='black')
)
# Remove spine for neatness
sns.despine()
plt.show()
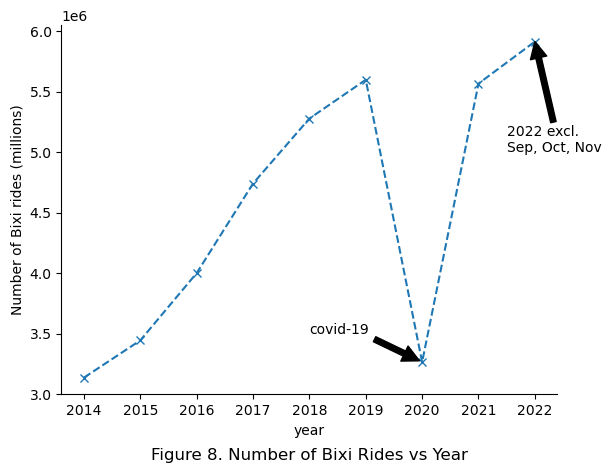
Note: further data cleaning, such as identifying rides that were too long or too short, have not yet been performed in above plot.
Interestingly, the number of Bixi rides were observed to increase over the years. An exception was the year 2020, which saw a significant dip in ridership most likely due to Covid-19 restrictions. Finally, the year 2022 was observed to have more rides than 2021 eventhough the rides for September, October and November were not included.
Pivot of Top 10 Start Stations by Year
In the next example, a pivot table containing the statistics for the top 10 stations in 2021 wascreated and compared against 2022 data. This information may be useful to understand how the top 10 stations in 2021 are being utilized in 2022.
To do this, Common Table Expressions (CTE) and window functions were used in the SQL query. Also, the SQL query demonstrates how the join table was used to gather station details. Finally, Python was used to create the pivot table, showing how MySQL and Python can be combined and accessed solely through Python for data analysis.
with engine.connect() as conn:
sql_stmt = sqlalchemy.text(
"""
# Create a common table expression to generate rankings for each station by ridership
WITH top_10_stn AS (
SELECT
YEAR(start_dt_utc) AS year,
start_stn_code,
DENSE_RANK() OVER(
PARTITION BY YEAR(start_dt_utc)
ORDER BY COUNT(*) DESC
) AS stn_ranking
FROM
rides
WHERE
YEAR(start_dt_utc) IN (2021,2022)
GROUP BY
year,
start_stn_code
)
SELECT
YEAR(a.start_dt_utc) AS year,
b.stn_ranking,
COUNT(*) AS number_of_rides,
ROUND(AVG(a.duration_sec),0) AS avg_duration,
a.start_stn_code,
a.company,
d.stn_name,
d.stn_lat,
d.stn_lon
FROM
rides AS a
# First inner join to filter stations in 2021 and 2022 only
INNER JOIN
top_10_stn AS b
ON
YEAR(a.start_dt_utc) = b.year
AND a.start_stn_code = b.start_stn_code
# Second left join to join table to connect with stations table
LEFT JOIN
jt_rides_stations AS c
ON
a.data_source = c.ride_files
# Third left join to get station data
LEFT JOIN
stations AS d
ON
c.station_files = d.data_source
AND a.start_stn_code = d.stn_code
# Filter to only keep top 10 ranking
WHERE
a.start_stn_code IN (
SELECT
DISTINCT(start_stn_code)
FROM
top_10_stn
WHERE
stn_ranking < 11
AND year = 2021
)
# Finally group by station code and year
GROUP BY
YEAR(a.start_dt_utc),
a.start_stn_code,
a.company,
d.stn_name,
d.stn_lat,
d.stn_lon
"""
)
# start_timer
start_time = time.perf_counter()
result_df = pd.read_sql(
sql_stmt,
con = conn)
# end_timer
end_time = time.perf_counter()
time_taken = np.round(end_time - start_time,3)
print(f"Time taken to run SQL query: {time_taken} seconds.")
Time taken to run SQL query: 129.007 seconds.
The returned table was examined below.
# Visually examine top 10 rows
result_df.head(10)
| year | stn_ranking | number_of_rides | avg_duration | start_stn_code | company | stn_name | stn_lat | stn_lon | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021 | 6 | 31543 | 674.0 | 167 | Bixi | Boyer / du Mont-Royal | 45.527432 | -73.579917 |
| 1 | 2021 | 1 | 48310 | 715.0 | 256 | Bixi | Métro Mont-Royal (Rivard / du Mont-Royal) | 45.524673 | -73.582550 |
| 2 | 2022 | 7 | 32234 | 721.0 | 214 | Bixi | Laurier / de Brébeuf | 45.532514 | -73.584811 |
| 3 | 2022 | 9 | 30203 | 723.0 | 316 | Bixi | Prince-Arthur / du Parc | 45.510590 | -73.575470 |
| 4 | 2021 | 5 | 31549 | 714.0 | 214 | Bixi | Laurier / de Brébeuf | 45.532514 | -73.584811 |
| 5 | 2021 | 4 | 32159 | 984.0 | 330 | Bixi | Parc Jeanne Mance (monument sir George-Etienne... | 45.514840 | -73.584779 |
| 6 | 2022 | 13 | 27479 | 785.0 | 169 | Bixi | de Brébeuf / du Mont-Royal | 45.529408 | -73.578154 |
| 7 | 2022 | 6 | 32644 | 720.0 | 167 | Bixi | Boyer / du Mont-Royal | 45.527432 | -73.579917 |
| 8 | 2022 | 2 | 36816 | 717.0 | 242 | Bixi | du Mont-Royal / Clark | 45.519410 | -73.586850 |
| 9 | 2022 | 8 | 31294 | 1037.0 | 330 | Bixi | Parc Jeanne Mance (monument sir George-Etienne... | 45.514840 | -73.584779 |
Finally, the returned table was passed through the pivot_table method to generate the desired pivot table.
# Generate pivot table from SQL data
pivot_df = pd.pivot_table(
data = result_df,
values = ['number_of_rides','avg_duration'],
index = ['stn_name'],
columns = ['year']
)
print(f"Average Duration and Number of Rides for Top 10 Stations in 2021 by Ridership:")
pivot_df.sort_values(
by = ('number_of_rides',2021),
ascending = [False])
Average Duration and Number of Rides for Top 10 Stations in 2021 by Ridership:
| avg_duration | number_of_rides | |||
|---|---|---|---|---|
| year | 2021 | 2022 | 2021 | 2022 |
| stn_name | ||||
| Métro Mont-Royal (Rivard / du Mont-Royal) | 715.0 | 741.0 | 48310 | 57124 |
| du Mont-Royal / Clark | 694.0 | 717.0 | 36256 | 36816 |
| Marquette / du Mont-Royal | 649.0 | 677.0 | 36052 | 36459 |
| Parc Jeanne Mance (monument sir George-Etienne Cartier) | 984.0 | 1037.0 | 32159 | 31294 |
| Laurier / de Brébeuf | 714.0 | 721.0 | 31549 | 32234 |
| Boyer / du Mont-Royal | 674.0 | 720.0 | 31543 | 32644 |
| Métro Atwater (Atwater / Ste-Catherine) | 882.0 | 864.0 | 30565 | 34642 |
| Métro Laurier (Rivard / Laurier) | 625.0 | 623.0 | 29762 | 11009 |
| Prince-Arthur / du Parc | 703.0 | 723.0 | 29076 | 30203 |
| de Brébeuf / du Mont-Royal | 722.0 | 785.0 | 26077 | 27479 |
From the pivot table, it was observed that the most popular station in 2021, Metro Mont-Royal (Rivard / du Mont-Royal), observed an 18% increase in ridership in 2022. Metro Laurier (Rovard / Laurier) on the other hand, saw a 62% decrease of ridership in 2022, warranting further investigation as to what is possibly causing the drastic reduction. All other of the top 10 stations were within 5% difference of ridership compared to 2021.
Conclusion
Using SQLAlchemy and Python, 41 million Bixi rides were extracted, transformed and loaded into MySQL in chunks. The ingested data was then accessed through SQL statements in Python for data analysis and visualization.
Future improvements:
- a circuit breaker, meaning a small test, can be implemented to ensure clean data is entering the data ingestion pipeline.
- makefiles can be used to automatically trigger the data ingestion process when new data is detected.
- Use of a distributed file system like Hadoop for parallelized processing of data to reduce query time.
References and Acknowledgements
- MySQL support : SQLAlchemy documentation
- StackOverflow :